January 29, 2020 — In this long post I'm going to do a stupid thing and see what happens. Specifically I'm going to create 6.5 million files in a single folder and try to use Git and Sublime and other tools with that folder. All to explore this new thing I'm working on.
TreeBase is a new system I am working on for long-term, strongly-typed collaborative knowledge bases. The design of TreeBase is dumb. It's just a folder with a bunch of files encoded with Tree Notation. A row in a normal SQL table in TreeBase is roughly equivalent to a file. The filenames serve as IDs. Instead of each using an optimized binary storage format it just uses plain text like UTF-8. Field names are stored alongside the values in every file. Instead of starting with a schema you can just start adding files and evolve your schema and types as you go.
For example, in this tiny demo TreeBase of the planets the file mars.planet looks like this:
diameter 6794
surfaceGravity 4
yearsToOrbitSun 1.881
moons 2
TreeBase is composed of 3 key ingredients.
Ingredient 1: A folder All that TreeBase requires is a file system (although in theory you could build an analog TreeBase on paper). This means that you can use any tools on your system for editing files for editing your database.
Ingredient 2: Git Instead of having code to implement any sort of versioning or metadata tracking, you just use Git. Edit your files and use Git for history, branching, collaboration, etc. Because Tree Notation is a line and word based syntax it meshes really well with Git workflows.
Ingredient 3: Tree Notation The Third Ingredient for making a TreeBase is Tree Notation. Both schemas and data use Tree Notation. This is a new very simple syntax for encoding strongly typed data. It's simple, extensible, and plays well with Git.
TreeBase Compared to Other Database Systems
Probably hundreds of billions of dollars has gone into designing robust database systems like SQL Server, Oracle, PostgreSQL, MySQL, MongoDB, SQLite and so forth. These things run the world. They are incredibly robust and battle-hardened. Everything that can happen is thought of and planned for, and everything that can go wrong has gone wrong (and learned from). These databases can handle trillions of rows, can conduct complex real-time transactions, and survive disasters of all sort. They use sophisticated binary formats and are tuned for specific file systems. Thousands of people have gotten their PhD's working on database technology.
TreeBase doesn't have any of that. TreeBase is stupid. It's just a bunch of files in a folder.
You might be asking yourself "Why use TreeBase at all when great databases exist?". To further put the stupidity of the current TreeBase design into perspective, the Largest Git Repo on the Planet is Windows which has 3.5 million files. I'm going to try and create a repo with 6.5 million files on my laptop.
Even if you think TreeBase is silly aren't you curious what happens when I try to put 6.5 million files into one folder? I kind of am. If you want an explanation of why TreeBase, I'll get to that near the end of this post.
But first...
Let's Break TreeBase
Here again is a demo TreeBase with only 8 files.
The biggest TreeBase I work with has on the order of 10,000 files. Some files have thousands of lines, some just a handful.
While TreeBase has been great at this small scale, a question I've been asked, and have wondered myself, is what happens when a TreeBase gets too big?
I'm about to find out, and I'll document the whole thing.
Every time something bad happens I'll include a 💣.
Choosing a Topic
TreeBase is meant for knowledge bases. So all TreeBases center around a topic.
To test TreeBase on a big scale I want something realistic. I wanted to choose some big structured database that thousands of people have contributed to that's been around for a while and see what it would look like as a TreeBase.
IMDB is just such a database and amazingly makes a lot of their data available for download. So movies will be the topic and the IMDB dataset will be my test case.
The Dataset
First I grabbed the data. I downloaded the 7 files from IMDB to my laptop. After unzipping, they were about 7GB.
One file, the 500MB title.basics.tsv, contained basic data for all the movie and shows in the database.
Here's what that file looks like with head -5 title.basics.tsv:
| tconst | titleType | primaryTitle | originalTitle | isAdult | startYear | endYear | runtimeMinutes | genres |
|---|---|---|---|---|---|---|---|---|
| tt0000001 | short | Carmencita | Carmencita | 0 | 1894 | \N | 1 | Documentary,Short |
| tt0000002 | short | Le clown et ses chiens | Le clown et ses chiens | 0 | 1892 | \N | 5 | Animation,Short |
| tt0000003 | short | Pauvre Pierrot | Pauvre Pierrot | 0 | 1892 | \N | 4 | Animation,Comedy,Romance |
| tt0000004 | short | Un bon bock | Un bon bock | 0 | 1892 | \N | \N | Animation,Short |
This looks like a good candidate for TreeBase. With this TSV I can create a file for each movie. I don't need the other 6 files for this experiment, though if this was a real project I'd like to merge in that data as well (in that case I'd probably create a second TreeBase for the names in the IMDB dataset).
Doing a simple line count wc -l title.basics.tsv I learn that there are around 6.5M titles in title.basics.tsv. With the current implementation of TreeBase this would be 6.5M files in 1 folder. That should handily break things.
The TreeBase design calls for me to create 1 file for every row in that TSV file. To again stress how dumb this design is keep in mind a 500MB TSV with 6.5M rows can be parsed and analyzed with tools like R or Python in seconds. You could even load the thing near instantly into a SQLite database and utilize any SQL tool to explore the dataset. Instead I am about to spend hours, perhaps days, turning it into a TreeBase.
From 1 File to 6.5 Million Files
What will happen when I split 1 file into 6.5 million files? Well, it's clear I am going to waste some space.
A file doesn't just take up space for its contents: it also has metadata. Every file contains metadata like permissions, modification time, etc. That metadata must take up some space, right? If I were to create 6.5M new files, how much extra space would that take up?
My MacBook uses APFS It can hold up to 9,000,000,000,000,000,000 files. I can't easily find hard numbers on how much metadata one file takes up but can at least start with a ballpark estimate.
I'll start by considering the space filenames will take up.
In TreeBase filenames are composed of a permalink and a file extension. The file extension is to make it easier for editors to understand the schema of a file. In the planets TreeBase above, the files all had the planet extension and there is a planet.grammar file that contains information for the tools like syntax highlighters and type checkers. For my new IMDB TreeBase there will be a similar title.grammar file and each file will have the ".title" extension. So that is 6 bytes per file. Or merely 36MB extra for the file extensions.
Next, the body of each filename will be a readable ID. TreeBase has meaningful filenames to work well with Git and existing file tools. It keeps things simple. For this TreeBase, I will make the ID from the primaryTitle column in the dataset. Let's see how much space that will take.
I'll try xsv select primaryTitle title.basics.tsv | wc.
💣 I got this error:
CSV error: record 1102213 (line: 1102214, byte: 91470022): found record with 8 fields, but the previous record has 9 fields
1102213 3564906 21815916
XSV didn't like something in that file. Instead of getting bogged down, I'll just work around it.
I'll build a subset from the first 1M rows with head -n 1000000 title.basics.tsv > 1m.title.basics.tsv. Now I will compute against that subset with xsv select primaryTitle 1m.title.basics.tsv | wc. I get 19751733 so an average of 20 characters per title.
I'll combine that with the space for file extension and round that to say 30 extra bytes of file information for each of the 6.5 million titles. So about 200MB of extra data required to split this 500MB file into filenames. Even though that's a 50% increase, 200MB is dirt cheap so that doesn't seem so bad.
You may think that I could save a roughly equivalent amount by dropping the primaryTitle field. However, even though my filenames now contain information from the title, my permalink schema will generally distort the title so I need to preserve it in each file and won't get savings there. I use a more restrictive character set in the permalink schema than the file contents just to make things like URLs easier.
Again you might ask why not just an integer for the permalink? You could but that's not the TreeBase way. The human readable permalinks play nice with tools like text editors, URLs, and Git. TreeBase is about leveraging software that already works well with file systems. If you use meaningless IDs for filenames you do away with one of the very useful features of the TreeBase system.
But I won't just waste space in metadata. I'm also going to add duplicate data to the contents of each file. That's because I won't be storing just values like 1999 but I'll also be repeating column names in each file like startYear 1999.
How much space will this take up? The titles file has 9 columns and using head -n 1 1m.title.basics.tsv | wc I see that adds up to 92 bytes. I'll round that up to 100, and multiple by 6.5M, and that adds up to about 65,000,000 duplicate words and 650MB. In other words the space requirements roughly doubled (of course, assuming no compression by the file system under the hood).
You might be wondering why not just drop the column names from each file? Again, it's just not the TreeBase way. By including the column names, each file is self-documenting. I can open up any file with a text editor and easily change it.
So to recap: splitting this 1 TSV file into 6.5 million files is going to take up 2-3x more space due to metadata and repetition of column names.
Because this is text data, that's actually not so bad. I don't foresee problems arising from wasted disk space.
Foreseeing Speed Problems
Before I get to the fun part, I'm going to stop for a second and try and predict what the problems are going to be.
Again, in this experiment I'm going to build and attempt to work with a TreeBase roughly 1,000 times larger than any I've worked with before. A 3 order of magnitude jump.
Disk space won't be a problem. But are the software tools I work with on a day-to-day basis designed to handle millions of files in a single folder? How will they hold up?
- Bash How will the basics like
lsandgrephold up in a folder with 6.5M files? - Git How slow will
git statusbe? What aboutgit addandgit commit? - Sublime Text Will I even be able to open this folder in Sublime Text? Find/replace is something I so commonly use, will that work? How about regex find/replace?
- Finder Will I be able to visually browse around?
- TreeBase Scripts Will my simple TreeBase scripts be usable? Will I be able to type check a TreeBase?
- GitHub Will GitHub be able to handle 6.5M files?
Proceeding in Stages
Since I am going to make a 3 order of magnitude jump, I figured it would be best to make those jumps one at a time.
Actually, to be smart, I will create 5 TreeBases and make 4 jumps. I'll make 1 small TreeBase for sanity checks and then four where I increase by 10x 3 times and see how things hold up.
First, I'll create 5 folders: mkdir 60; mkdir 6k; mkdir 60k; mkdir 600k; mkdir 6m
Now I'll create 4 smaller subsets for the smaller bases. For the final 6.5M base I'll just use the original file.
head -n 60 title.basics.tsv > 60/titles.tsv
head -n 6000 title.basics.tsv > 6k/titles.tsv
head -n 60000 title.basics.tsv > 60k/titles.tsv
head -n 600000 title.basics.tsv > 600k/titles.tsv
Now I'll write a script to turn those TSV rows into TreeBase files.
#! /usr/local/bin/node --use_strict
const { jtree } = require("jtree")
const { Disk } = require("jtree/products/Disk.node.js")
const folder = "600k"
const path = `${__dirname}/../imdb/${folder}.titles.tsv`
const tree = jtree.TreeNode.fromTsv(Disk.read(path).trim())
const permalinkSet = new Set()
tree.forEach(node => {
let permalink = jtree.Utils.stringToPermalink(node.get("primaryTitle"))
let counter = ""
let dash = ""
while (permalinkSet.has(permalink + dash + counter)) {
dash = "-"
counter = counter ? counter + 1 : 2
}
const finalPermalink = permalink + dash + counter
permalinkSet.add(finalPermalink)
// Delete Null values:
node.forEach(field => {
if (field.getContent() === "\\N") field.destroy()
})
if (node.get("originalTitle") === node.get("primaryTitle")) node.getNode("originalTitle").destroy()
Disk.write(`${__dirname}/../imdb/${folder}/${finalPermalink}.title`, node.childrenToString())
})
The script iterates over each node and creates a file for each row in the TSV.
This script required a few design decisions. For permalink uniqueness, I simply keep a set of titles and number them if a name comes up multiple times. There's also the question of what to do with nulls. IMDB sets the value to \N. Generally the TreeBase way is to not include the field in question. So I filtered out null values. For cases where primaryTitle === originalTitle, I stripped the latter. For the Genres field, it's a CSV array. I'd like to make that follow the TreeBase convention of a SSV. I don't know all the possibilities though without iterating, so I'll just skip this for now.
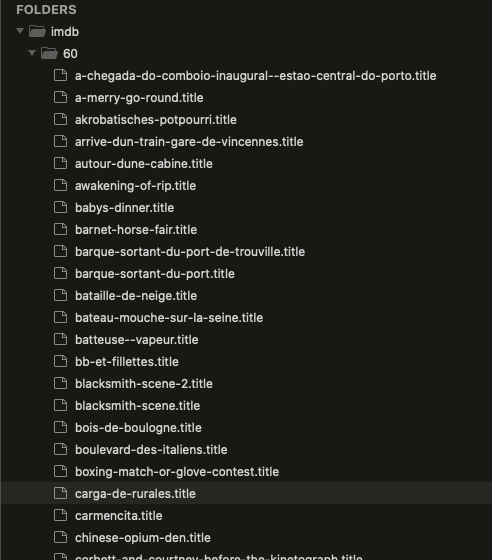
Here are the results of the script for the small 60 file TreeBase:
Building the Grammar File
The Grammar file adds some intelligence to a TreeBase. You can think of it as the schema for your base. TreeBase scripts can read those Grammar files and then do things like provide type checking or syntax highlighting.
Now that we have a sample title file, I'm going to take a first pass at the grammar file for our TreeBase. I copied the file the-photographical-congress-arrives-in-lyon.title and pasted it into the right side of the Tree Language Designer. Then I clicked Infer Prefix Grammar.
That gave me a decent starting point for the grammar:
inferredLanguageNode
root
inScope tconstNode titleTypeNode primaryTitleNode originalTitleNode isAdultNode startYearNode runtimeMinutesNode genresNode
keywordCell
anyCell
bitCell
intCell
tconstNode
crux tconst
cells keywordCell anyCell
titleTypeNode
crux titleType
cells keywordCell anyCell
primaryTitleNode
crux primaryTitle
cells keywordCell anyCell anyCell anyCell anyCell anyCell anyCell
originalTitleNode
crux originalTitle
cells keywordCell anyCell anyCell anyCell anyCell anyCell anyCell anyCell anyCell
isAdultNode
crux isAdult
cells keywordCell bitCell
startYearNode
crux startYear
cells keywordCell intCell
runtimeMinutesNode
crux runtimeMinutes
cells keywordCell bitCell
genresNode
crux genres
cells keywordCell anyCell
The generated grammar needed a little work. I renamed the root node and added catchAlls and a base "abstractFactType". The Grammar language and tooling for TreeBase is very new, so all that should improve as time goes on.
My title.grammar file now looks like this:
titleNode
root
pattern \.title$
inScope abstractFactNode
keywordCell
anyCell
bitCell
intCell
abstractFactNode
abstract
cells keywordCell anyCell
tconstNode
crux tconst
extends abstractFactNode
titleTypeNode
crux titleType
extends abstractFactNode
primaryTitleNode
crux primaryTitle
extends abstractFactNode
catchAllCellType anyCell
originalTitleNode
crux originalTitle
extends abstractFactNode
catchAllCellType anyCell
isAdultNode
crux isAdult
cells keywordCell bitCell
extends abstractFactNode
startYearNode
crux startYear
cells keywordCell intCell
extends abstractFactNode
runtimeMinutesNode
crux runtimeMinutes
cells keywordCell intCell
extends abstractFactNode
genresNode
crux genres
cells keywordCell anyCell
extends abstractFactNode
Next I coped that file into the 60 folder with cp /Users/breck/imdb/title.grammar 60/. I have the jtree package installed on my local machine so I registered this new language with that with the command jtree register /Users/breck/imdb/title.grammar. Finally, I generated a Sublime syntax file for these title files with jtree sublime title #pathToMySublimePluginDir.
Now I have rudimentary syntax highlighting for these new title files:
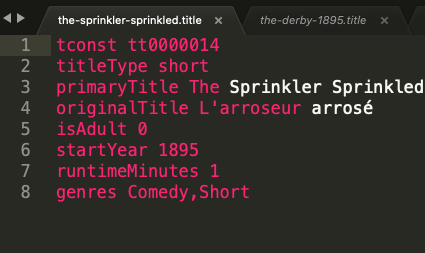
Notice the syntax highlighting is a little broken. The Sublime syntax generating still needs some work.
Anyway, now we've got the basics done. We have a script for turning our CSV rows into Tree Notation files and we have a basic schema/grammar for our new TreeBase.
Let's get started with the bigger tests now.
A 6k TreeBase
I'm expecting this to be an easy one. I update my script to target the 6k files and run it with /Users/breck/imdb/build.js. A little alarmingly, it takes a couple of seconds to run:
real 0m3.144s
user 0m1.203s
sys 0m1.646s
The main script is going to iterate over 1,000x as many items so if this rate holds up it would take 50 minutes to generate the 6M TreeBase!
I do have some optimization ideas in mind, but for now let's explore the results.
First, let me build a catalog of typical tasks that I do with TreeBase that I will try to repeat with the 6k, 60k, 600k, and 6.5M TreeBases.
I'll just list them in Tree Notation:
task ls
category bash
description
task open sublime
category sublime
description Start sublime in the TreeBase folder
task sublime responsiveness
category sublime
description scroll and click around files in the treebase folder and see how responsive it feels.
task sublime search
category sublime
description find all movies with the query "titleType movie"
task sublime regex search
category sublime
description find all comedy movies with the regex query "genres ._Comedy._"
task open finder
category finder
description open the folder in finder and browse around
task git init
category git
description init git for the treebase
task git first status
category git
description see git status
task git first add
category git
description first git add for the treebase
task git first commit
category git
description first git commit
task sublime editing
category sublime
description edit some file
task git status
category git
description git status when there is a change
task git add
category git
description add the change above
task git commit
category git
description commit the change
task github push
category github
description push the treebase to github
task treebase start
category treebase
description how long will it take to start treebase
task treebase error check
category treebase
description how long will it take to scan the base for errors.
💣 Before I get to the results, let me note I had 2 bugs. First I needed to update my title.grammar file by adding a cells fileNameCell to the root node and also adding a fileNameCell line. Second, my strategy above of putting the CSV file for each TreeBase into the same folder as the TreeBase was not ideal as Sublime Text would open that file as well. So I moved each file up with mv titles.tsv ../6k.titles.tsv.
The results for 6k are below.
| category | description | result |
|---|---|---|
| bash | ls | instant |
| sublime | Start sublime in the TreeBase folder | instant |
| sublime | scroll and click around files in the treebase folder and see how responsive it feels. | nearInstant |
| sublime | find all movies with the query "titleType movie" | neaerInstant |
| sublime | find all comedy movies with the regex query "genres ._Comedy._" | nearInstant |
| finder | open and browse | instant |
| git | init git for the treebase | instant |
| git | see git status | instant |
| git | first git add for the treebase | aFewSeconds |
| git | first git commit | instant |
| sublime | edit some file | instant |
| git | git status when there is a change | instant |
| git | add the change above | instant |
| git | commit the change | instant |
| github | push the treebase to github | ~10 seconds |
| treebase | how long will it take to start treebase | instant |
| treebase | how long will it take to scan the base for errors. | nearInstant |
So 6k worked without a hitch. Not surprising as this is in the ballpark of where I normally operate with TreeBases.
Now for the first of three 10x jumps.
A 60k TreeBase
💣 This markdown file that I'm writing was in the parent folder of the 60k directory and Sublime text seemed to be slowing a bit, so I closed Sublime and created a new unrelated folder to hold this writeup separate from the TreeBase folders.
The build script for the 60k TreeBase took 30 seconds or so, as expected. I can optimize for that later.
I now repeat the tasks from above to see how things are holding up.
| category | description | result |
|---|---|---|
| bash | ls | aFewSeconds |
| sublime | Start sublime in the TreeBase folder | aFewSeconds with Beachball |
| sublime | scroll and click around files in the treebase folder and see how responsive it feels. | instant |
| sublime | find all movies with the query "titleType movie" | ~20 seconds with beachball |
| sublime | find all comedy movies with the regex query "genres ._Comedy._" | ~20 seconds with beachball |
| git | init git for the treebase | instant |
| finder | open and browse | 6 seconds |
| git | see git status | nearInstant |
| git | first git add for the treebase | 1 minute |
| git | first git commit | 10 seconds |
| sublime | edit some file | instant |
| git | git status when there is a change | instant |
| git | add the change above | instant |
| git | commit the change | instant |
| github | push the treebase to github | ~10 seconds |
| treebase | how long will it take to start treebase | ~10 seconds |
| treebase | how long will it take to scan the base for errors. | ~5 seconds |
Uh oh. Already I am noticing some scaling delays with a few of these tasks.
💣 The first git add took about 1 minute. I used to know the internals of Git well but that was a decade ago and my knowledge is rusty.
I will now look some stuff up. Could Git be creating 1 file for each file in my TreeBase? I found this post from someone who created a Git repo with 1.7M files which should turn out to contain useful information. From that post it looks like you can indeed expect 1 file for Git for each file in the project.
The first git commit took about 10 seconds. Why? Git printed a message about Autopacking. It seems Git will combine a lot of small files into packs (perhaps in bundles of 6,700, though I haven't dug in to this) to speed things up. Makes sense.
💣 I forgot to mention, while doing the tasks for the 60k TreeBase, my computer fan kicked on. A brief look at Activity Monitor showed a number of mdworker_shared processes using single digit CPU percentages each, which appears to be some OS level indexing process. That's hinting that a bigger TreeBase might require at least some basic OS/file system config'ing.
Besides the delays with git everything else seemed to remain fast. The 60k TreeBase choked a little more than I'd like but seems with a few tweaks things could remain screaming fast.
Let's move on to the first real challenge.
A 600k TreeBase
💣 The first problem I hit immediately in that my build.js is not efficient. I hit a v8 out of memory error. I could solve this by either 1) streaming the TSV one row at a time or 2) cleaning up the unoptimized jtree library to handle bigger data better. I chose to spend a few minutes and go with option 1).
💣 It appears the first build script started writing files to the 600k directory before it failed. I had to rm -rf 600k/ and that took a surprisingly long time. Probably a minute or so. Something to keep an eye on.
💣 I updated my build script to use streams. Unfortunately the streaming csv parser I switched to choked on line 32546. Inspecting that vicinity it was hard to detect what it was breaking on. Before diving in I figured I'd try a different library.
💣 The new library seemed to be working but it was taking a while so I added some instrumentation to the script. From those logs the new script seems to generate about 1.5k files per second. So should take about 6 minutes for all 600k. For the 6.5M files, that would grow to an hour, so perhaps there's more optimization work to be done here.
💣 Unfortunately the script exited early with:
Error: ENAMETOOLONG: name too long, open '/Users/breck/imdbPost/../imdb/600k/mord-an-lottomillionr-karl-hinrich-charly-l.sexualdelikt-an-carola-b.bankangestellter-zweimal-vom-selben-bankruber-berfallenmord-an-lottomillionr-karl-hinrich-charly-l.sexualdelikt-an-carola-b.bankangestellter-zweimal-vom-selben-bankruber-berfallen01985nncrimenews.title'
Turns out the Apple File System has a filename size limit of 255 UTF-8 characters so this error is understandable. However, inspecting the filename shows that for some reason the permalink was generated by combining the original title with the primary title. Sounds like a bug.
I cd into the 600k directory to see what's going on.
💣 Unfortunately ls hangs. ls -f -1 -U seems to go faster.
The titles look correct. I'm not sure why the script got hung up on that one entry. For now I'll just wrap the function call in a Try/Catch and press on. I should probably make this script resumable but will skip that for now.
Rerunning the script...it worked! That line seemed to be the only problematic line.
We now have our 600k TreeBase.
| category | description | result |
|---|---|---|
| bash | ls | ~30 seconds |
| sublime | Start sublime in the TreeBase folder | failed |
| sublime | scroll and click around files in the treebase folder and see how responsive it feels. | X |
| sublime | find all movies with the query "titleType movie" | X |
| sublime | find all comedy movies with the regex query "genres ._Comedy._" | X |
| finder | open and browse | 3 minutes |
| git | init git for the treebase | nearInstant |
| git | see git status | 6s |
| git | first git add for the treebase | 40 minutes |
| git | first git commit | 10 minutes |
| sublime | edit some file | X |
| git | git status when there is a change | instant |
| git | add the change above | instant |
| git | commit the change | instant |
| github | push the treebase to github | ~10 seconds |
| treebase | how long will it take to start treebase | ~10 seconds |
| treebase | how long will it take to scan the base for errors. | ~5 seconds |
💣 ls is now nearly unusable. ls -f -1 -U takes about 30 seconds. A straight up ls takes about 45s.
💣 Sublime Text failed to open. After 10 minutes of 100% CPU usage and beachball'ing I force quit the program. I tried twice to be sure with the same result.
💣 mdworker_shared again kept my laptop running hot. I found a way of potentially disabling Mac OS X Spotlight Indexing of the IMDB folder.
💣 Opening the 600k folder in Apple's Finder gave me a loading screen for about 3 minutes
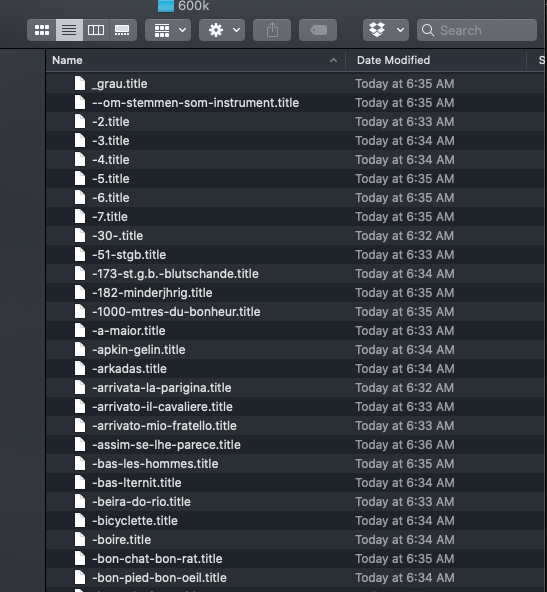
At least it eventually came up:
Now, how about Git?
💣 The first git add . took 40 minutes! Yikes.
real 39m30.215s
user 1m19.968s
sys 13m49.157s
💣 git status after the initial git add took about a minute.
💣 The first git commit after the git add took about 10 minutes.
GitHub turns out to be a real champ. Even with 600k files the first git push took less than 30 seconds.
real 0m22.406s
user 0m2.657s
sys 0m1.724s
The 600k repo on GitHub comes up near instantly. GitHub just shows the first 1k out of 600k files which I think is a good compromise, and far better than a multiple minute loading screen.
💣 Sadly there doesn't seem to be any pagination for this situation on GitHub, so not sure how to view the rest of the directory contents.
I can pull up a file quickly on GitHub, like the entry for License to Kill.
How about editing files locally? Sublime is no use so I'll use vim. Because ls is so slow, I'll find the file I want to edit on GitHub. Of course because I can't find pagination in GitHub I'll be limited to editing one of the first 1k files. I'll use just that License to Kill entry.
So the command I use vim 007-licence-to-kill.title. Editing that file is simple enough. Though I wish we had support for Tree Notation in vim to get syntax highlighting and such.
💣 Now I do git add .. Again this takes a while. What I now realize is that my fancy command prompt does some git status with every command. So let's disable that.
After going in and cleaning up my shell (including switching to zsh) I've got a bit more performance back on the command line.
💣 But just a bit. A git status still takes about 23 seconds! Even with the -uno option it takes about 15 seconds. This is with 1 modified file.
Now adding this 1 file seems tricky. Most of the time I do a git status and see that I want to add everything so I do a git add ..
💣 But I tried git add . in the 600k TreeBase and after 100 seconds I killed the job. Instead I resorted to git add 007-licence-to-kill.title which worked pretty much instantly.
💣 git commit for this 1 change took about 20 seconds. Not too bad but much worse than normal.
git push was just a few seconds.
I was able to see the change on GitHub instantly. Editing that file on GitHub and committing was a breeze. Looking at the change history and blame on GitHub was near instant.
Git blame locally was also just a couple of seconds.
Pause to Reflect
So TreeBase struggles at the 600k level. You cannot just use TreeBase at the 100k level without preparing your system for it. Issues arise with GUIs like Finder and Sublime, background file system processes, shells, git, basic bash utilities, and so forth.
I haven't looked yet into RAM based file systems or how to setup my system to make this use case work well, but for now, out of the box, I cannot recommend TreeBase for databases of more than 100,000 entities.
Is there even a point now to try 6.5M? Arguably no.
However, I've come this far! No turning back now.
A 6.5M TreeBase
To recap what I am doing here: I am taking a single 6.5 million row 500MB TSV file that could easily be parsed into a SQLite or other battle hardened database and instead turning it into a monstrous 6.5 million file TreeBase backed by Git and writing it to my hard disk with no special configuration.
By the way, I forgot to mention my system specs for the record. I'm doing this on a MacBook Air running macOS Catalina on a 2.2Ghz Dual-core i7 with 8GB of 1600 Mhz DDR3 Ram with a 500GB Apple SSD using APFS. This is the last MacBook with a great keyboard, so I really hope it doesn't break.
Okay, back to the task at hand.
I need to generate the 6.5M files in a single directory. The 600k TreeBase took 6 minutes to generate so if that scales linearly 6.5M should take an hour. The first git add for 600k took 40 minutes, so that for 6.5M could take 6 hours. The first git commit for 600k took 10 minutes, so potentially 1.5 hours for 6.5M. So this little operation might take about 10 hours.
I'll stitch these operations together into a shell script and run it overnight (I'll make sure to check the batteries in my smoke detectors first).
Here's the script to run the whole routine:
time node buildStream.js
time cd ~/imdb/6m/
time git add .
time git commit -m "initial commit"
time git push
Whenever running a long script, it's smart to test it with a smaller dataset first. I successfully tested this script with the 6k file dataset. Everything worked. Everything should be all set for the final test.
(Later the next day...)
It's Alive!
It worked!!! I now have a TreeBase with over 6 million files in a single directory. Well, a few things worked, most things did not.
| category | description | result |
|---|---|---|
| bash | ls | X |
| sublime | Start sublime in the TreeBase folder | X |
| sublime | scroll and click around files in the treebase folder and see how responsive it feels. | X |
| sublime | find all movies with the query "titleType movie" | X |
| sublime | find all comedy movies with the regex query "genres ._Comedy._" | X |
| finder | open and browse | X |
| git | init git for the treebase | nearInstant |
| git | first git add for the treebase | 12 hours |
| git | first git commit | 5 hours |
| sublime | edit some file | X |
| git | git status when there is a change | X |
| git | add the change above | X |
| git | commit the change | X |
| github | push the treebase to github | X |
| treebase | how long will it take to start treebase | X |
| treebase | how long will it take to scan the base for errors. | X |
💣 There was a slight hiccup in my script where somehow v8 again ran out of memory. But only after creating 6,340,000 files, which is good enough for my purposes.
💣 But boy was this slow! The creation of the 6M+ files took 3 hours and 20 minutes.
💣 The first git add . took a whopping 12 hours!
💣 The first git commit took 5 hours!
💣 A few times when I checked on the machine it was running hot. Not sure if from CPU or Disk or a combination.
💣 I eventually quit git push. It quickly completed Counting objects: 6350437, done. but then nothing happened except lots of CPU usage for hours.
Although most programs failed, I was at least able to successfully create this monstrosity and navigate the folder.
The experiment has completed. I took a perfectly usable 6.5M row TSV file and transformed it into a beast that brings some of the most well-known programs out there to their knees.
💣 NOTE: I do not recommend trying this at home. My laptop became lava hot at points. Who knows what wear and tear I added to my hard disk.
What have I learned?
So that is the end of the experiment. Can you build a Git-backed TreeBase with 6.5M files in a single folder? Yes. Should you? No. Most of your tools won't work or will be far too slow. There's infrastructure and design work to be done.
I was actually pleasantly surprised by the results of this early test. I was confident it was going to fail but I wasn't sure exactly how it would fail and at what scale. Now I have a better idea of that. TreeBase currently sucks at the 100k level.
I also now know that the hardware for this type of system feels ready and it's just parts of some software systems that need to be adapted to handle folders with lots of files. I think those software improvements across the stack will be made and this dumb thing could indeed scale.
What's Next?
Now, my focus at the moment is not on big TreeBases. My focus is on making the experience of working with little TreeBases great. I want to help get things like Language Server Protocol going for TreeBases and a Content Management System backed by TreeBase.
But I now can envision how, once the tiny TreeBase experience is nailed, you should be able to use this for bigger tasks. The infrastructure is there to make it feasible with just a few adjustments. There are some config tweaks that can be made, more in-memory approaches, and some straightforward algorithmic additions to make to a few pieces of software. I also have had some fun conversations where people have suggested good sharding strategies that may prove useful without changing the simplicity of the system.
That being said, it would be fun to do this experiment again but this time try and make it work. Once that's a success, it would be fun to try and scale it another 100x, and try to build a TreeBase for something like the 180M paper Semantic Scholar dataset.
Why Oh Why TreeBase?
Okay, you might be wondering what is the point of this system? Specifically, why use the file system and why use Tree Notation?
1) The File System is Going to Be Here for a Long Long Time
1) About 30m programmers use approximately 100 to 500 general purpose programming languages. All of these actively used general purpose languages have battle tested APIs for interacting with file systems. They don't all have interfaces to every database program. Any programmer, no matter what language they use, without having to learn a new protocol, language, or package, could write code to interact with a TreeBase using knowledge they already have. Almost every programmer uses Git now as well, so they'd be familiar with how TreeBase change control works.
2) Over one billion more casual users are familiar with using their operating system tools for interacting with Files (like Explorer and Finder). Wouldn't it be cool if they could use tools they already know to interact with structured data?
Wouldn't it be cool if we could combine sophisticated type checking, querying, and analytical capabilities of databases with the simplicity of files? Programmers can easily build GUIs on top of TreeBase that have any and all of the functionality of traditional database-backed programs but have the additional advantage of an extremely well-known access vector to their information.
People have been predicting the death of files but these predictions are wrong. Even Apple recently backtracked and added a Files interface to iOS. Files and folders aren't going anywhere. It's a very simple and useful design pattern that works in the analog and digital realm. Files have been around for at least 4,500 years and my guess is will be around for another 5,000 years, if the earth doesn't blow up. Instead of dying, on the contrary file systems will keep getting better and better.
2) Tree Notation is All You Need to Create Meaningful Semantic Content
People have recognized the value of semantic, strongly typed content for a long time. Databases have been strongly typed since the beginning of databases. Strongly typed programming languages have dominated the software world since the beginning of software.
People have been attempting to build a system for collaborative semantic content for decades. XML, RDF, OWL2, JSON-LD, Schema.org—these are all great projects. I just think they can be simplified and I think one strong refinement is Tree Notation.
I imagine a world where you can effortlessly pass TreeBases around and combine them in interesting ways. As a kid I used to collect baseball cards. I think it would be cool if you could just as easily pass around "cards" like a "TreeBase of all the World's Medicines" or a "TreeBase of all the world's academic papers" or a "TreeBase of all the world's chemical compounds" and because I know how to work with one TreeBase I could get value out of any of these TreeBases. Unlike books or weakly typed content like Wikipedia, TreeBases are computable. They are like specialized little brains that you can build smart things out of.
So I think this could be pretty cool. As dumb as it is.
I would love to hear your thoughts.